LLM 추론 성능 MI300 vs H100 | 비용과 성능 완벽 비교
LLM 추론 성능 MI300 vs H100 경쟁이 심화되는 가운데, 기업들은 총소유비용(TCO)과 실제 워크로드 효율성을 기준으로 최적의 GPU를 선택해야 합니다. AMD의 MI300X는 압도적인 메모리 용량과 대역폭을 앞세워 NVIDIA H100의 강력한 대항마로 부상했습니다. 이 글은 최신 MLPerf 벤치마크, Llama 3.1 모델 기반 실측 데이터, 그리고 토큰당 비용 분석을 통해 당신의 비즈니스에 가장 적합한 GPU를 선택할 수 있도록 객관적이고 실용적인 가이드를 제공합니다.
이 글에서 바로 확인할 내용
- 핵심은 메모리: MI300X vs H100 하드웨어 스펙 비교 분석에서 확인해야 할 핵심 기준
- 메모리 용량 및 대역폭: MI300X의 명확한 우위에서 확인해야 할 핵심 기준
- 하드웨어 스펙 비교표에서 확인해야 할 핵심 기준
- 표준 벤치마크 대결: MI300 MLPerf 결과 분석에서 확인해야 할 핵심 기준
1. 핵심은 메모리: MI300X vs H100 하드웨어 스펙 비교 분석
두 GPU의 성능 차이를 만드는 가장 근본적인 요인은 하드웨어 구조, 특히 메모리에 있습니다. LLM 추론 성능은 모델 전체를 얼마나 빠르고 효율적으로 메모리에 올려놓고 처리하는지에 따라 결정되기 때문입니다.

메모리 용량 및 대역폭: MI300X의 명확한 우위
가장 눈에 띄는 차이점은 메모리 용량입니다. AMD MI300X는 192GB의 HBM3 메모리를 탑재하여 NVIDIA H100의 80GB HBM3보다 2.4배 더 큰 용량을 제공합니다. 이 압도적인 메모리 용량은 Llama 3.1 70B와 같은 거대 언어 모델을 처리할 때 결정적인 이점으로 작용합니다. 더 큰 모델을 단일 GPU에 올려두고 더 큰 배치 사이즈(Batch Size)로 요청을 처리할 수 있으며, 여러 모델을 동시에 서비스하는 다중 테넌트 환경에서도 병목 현상 없이 안정적인 성능을 유지할 수 있습니다.
메모리 대역폭 또한 MI300X가 5.3 TB/s로, H100의 3.35 TB/s보다 약 58% 더 넓습니다. 이는 모델의 가중치(파라미터)를 더 빠르게 읽어와 연산 코어에 전달할 수 있다는 의미로, 대규모 데이터를 쉴 새 없이 처리해야 하는 추론 워크로드에서 지연 시간을 줄이는 데 핵심적인 역할을 합니다.

하드웨어 스펙 비교표
| 항목 | AMD Instinct MI300X | NVIDIA H100 (SXM5) | 비고 |
|---|---|---|---|
| 아키텍처 | CDNA 3 | Hopper | AMD의 칩렛 구조 vs NVIDIA의 모놀리식 |
| 메모리 용량 | 192GB HBM3 | 80GB HBM3 | MI300X가 2.4배 우위 |
| 메모리 대역폭 | 5.3 TB/s | 3.35 TB/s | MI300X가 1.58배 우위 |
| FP16/BF16 성능 | 1,966 TFLOPS | 1,979 TFLOPS | 이론적 수치는 비슷하나 소프트웨어 최적화가 관건 |
| TDP | 750W (OAM) | 700W (SXM) | 전력 소모량은 비슷, 와트당 성능이 중요 |
이론적인 컴퓨팅 성능(TFLOPS)은 두 GPU가 비슷하지만, 실제 성능은 소프트웨어 최적화 수준에 따라 크게 달라집니다. NVIDIA는 Hopper 아키텍처와 Tensor Core를 통해 강력한 성능을 발휘하며, AMD는 CDNA 3 아키텍처와 Matrix Core로 이를 추격하고 있습니다. 전력 소비(TDP) 역시 비슷하지만, 실제 운영 환경에서는 성능당 전력 소비(Performance per Watt)가 TCO에 더 큰 영향을 미치므로, 이는 비용 분석 섹션에서 더 자세히 살펴보겠습니다.
2. 표준 벤치마크 대결: MI300 MLPerf 결과 분석
객관적인 성능 비교를 위해 가장 널리 인용되는 지표는 바로 MLPerf 벤치마크입니다. MI300 MLPerf 결과 분석은 AMD가 AI 추론 시장에서 NVIDIA의 대항마로 자리매김할 수 있음을 보여주는 중요한 사건이었습니다.
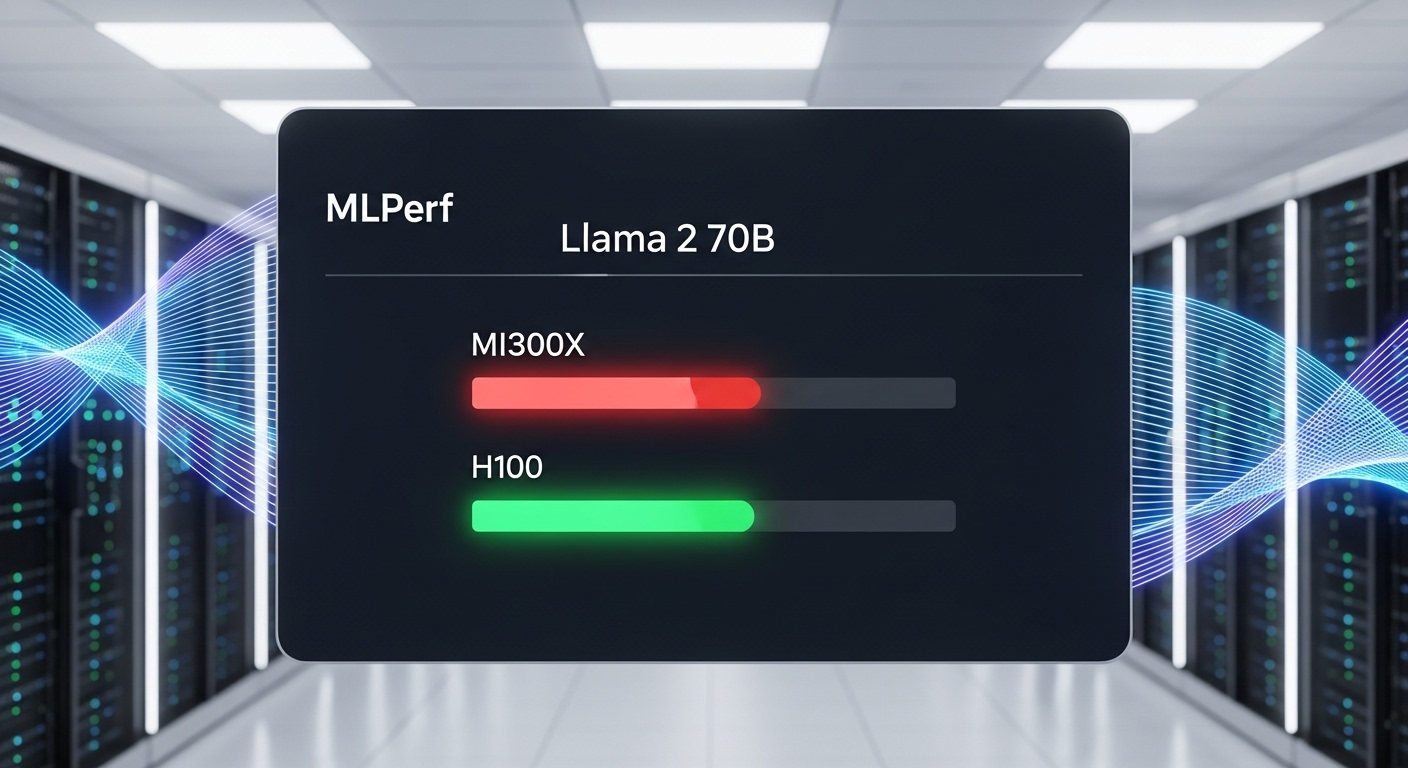
MLPerf Inference v4.0 Llama 2 70B 결과
AMD가 처음으로 공식 제출한 MLPerf Inference v4.0 결과는 시장에 큰 파장을 일으켰습니다. 특히 Llama 2 70B 모델을 사용한 서버 처리량(Offline) 테스트에서, 8개의 MI300X GPU로 구성된 Dell PowerEdge XE9680 서버는 8개의 H100 GPU 시스템 대비 1.3배 더 높은 처리량을 기록했습니다. 이는 단순히 하드웨어의 잠재력을 보여주는 것을 넘어, AMD의 ROCm 소프트웨어 스택과 vLLM과 같은 오픈소스 추론 프레임워크가 성숙 단계에 접어들었음을 증명하는 결과입니다.
하지만 NVIDIA의 반격도 만만치 않았습니다. NVIDIA는 자체 개발한 추론 최적화 라이브러리인 TensorRT-LLM을 사용했을 때 H100이 여전히 최고의 성능을 보인다고 주장했습니다. 실제로 동일한 MLPerf 테스트에서 NVIDIA가 직접 제출한 결과는 AMD의 기록을 상회했습니다. 이는 하드웨어만큼이나 소프트웨어 최적화가 LLM 추론 성능 MI300 vs H100 경쟁에서 얼마나 중요한 변수인지 명확하게 보여줍니다.
이러한 벤치마크 결과는 특정 조건 하에서 측정된 최대 성능치라는 점을 기억해야 합니다. 실제 운영 환경은 훨씬 더 다양하고 복잡한 변수들이 존재하기에, MLPerf 결과는 중요한 참고 자료로 활용하되 맹신해서는 안 됩니다. 따라서 다음 섹션에서는 실제 모델과 라이브러리를 사용한 실전 성능을 비교해 보겠습니다.
3. 실전 성능 검증: 실제 LLM에서의 추론 성능 MI300 vs H100
표준 벤치마크를 넘어, 현재 가장 널리 사용되는 Llama 3.1 모델과 vLLM 라이브러리 환경에서 두 GPU의 실질적인 성능을 비교 분석해 보겠습니다. 이 결과는 실제 AI 서비스를 구축하려는 개발자들에게 가장 직접적인 참고 자료가 될 것입니다.
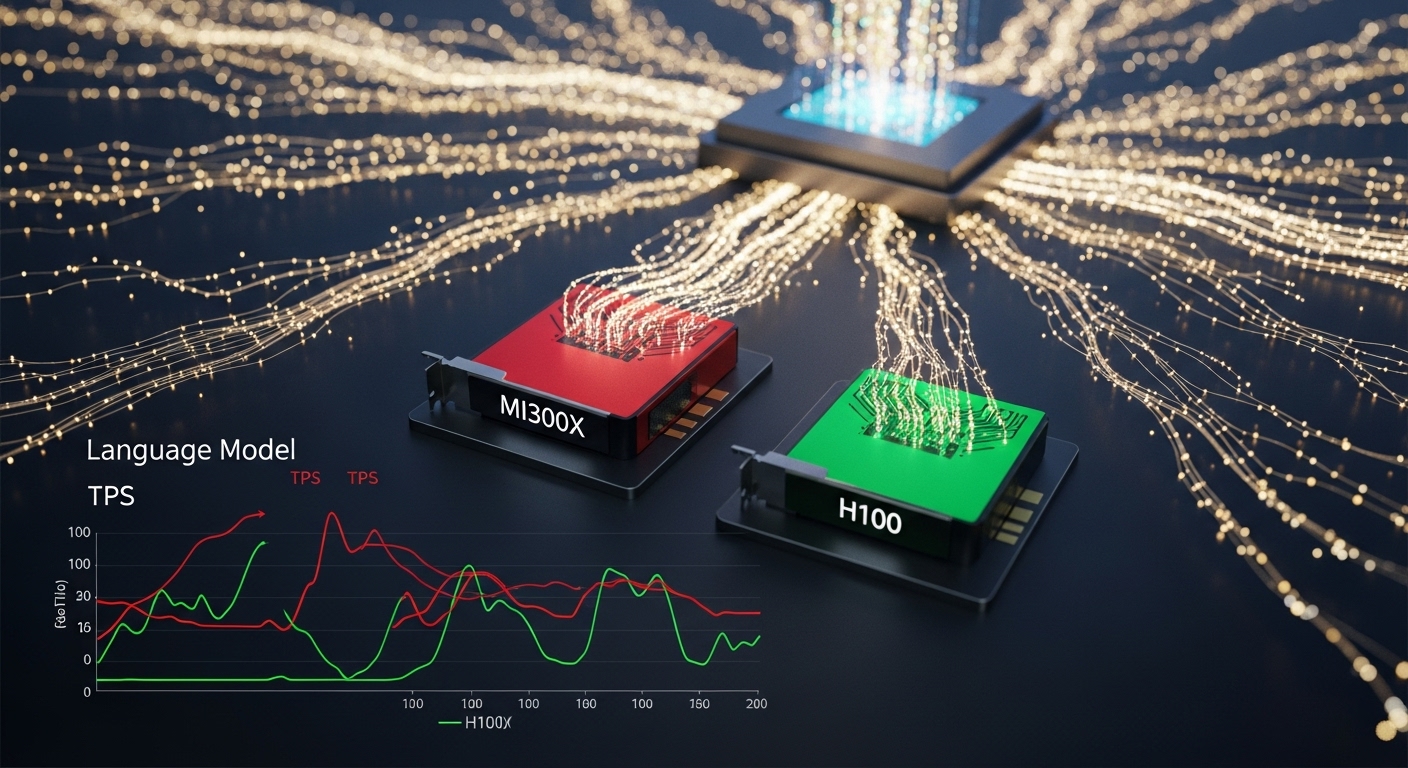
Llama 3.1 70B 모델 추론 성능 (vLLM 기준)
최신 벤치마크에 따르면, 널리 사용되는 오픈소스 추론 라이브러리인 vLLM 환경에서 단일 MI300X가 H100 대비 약 30% 더 높은 초당 토큰 처리량(TPS)을 보이는 것으로 나타났습니다. 이는 MI300X의 월등한 메모리 용량과 대역폭 덕분에 더 많은 사용자 요청을 한 번에 묶어 처리하는 '배치(Batch)'의 크기를 늘릴 수 있었기 때문입니다. 더 큰 배치 사이즈는 GPU의 연산 유닛을 쉬지 않고 가동시켜 전체적인 처리 효율을 극대화합니다.
배치 사이즈에 따른 성능 변화
두 GPU의 성능 양상은 배치 사이즈에 따라 달라집니다.
- 낮은 배치 사이즈 (실시간 채팅 등): 소수의 사용자 요청을 즉시 처리해야 하는 환경에서는 H100이 지연 시간(Latency) 면에서 미세한 우위를 보일 수 있습니다. 이는 NVIDIA의 성숙한 드라이버와 CUDA 소프트웨어 스택 덕분입니다.
- 높은 배치 사이즈 (대규모 서비스 등): 수백, 수천 명의 동시 요청을 처리해야 하는 환경에서는 배치 사이즈가 커질수록 MI300X의 TPS가 H100을 크게 앞지르기 시작합니다. 메모리 대역폭의 차이가 성능 차이로 직접 이어지는 구간입니다.
이처럼 소프트웨어 스택의 영향력도 무시할 수 없습니다. H100은 NVIDIA가 직접 개발한 TensorRT-LLM과 함께 사용할 때 최고의 성능을 발휘하는 반면, MI300X는 ROCm을 기반으로 vLLM, SGLang 등 다양한 오픈소스 프레임워크와의 호환성을 빠르게 개선하며 생태계를 확장하고 있습니다.
4. TCO의 핵심: 추론 TPS 토큰당 비용 비교 (AMD vs NVIDIA)
궁극적으로 기업에게 중요한 것은 성능 그 자체가 아니라 '비용 대비 성능'입니다. 추론 TPS 토큰당 비용 비교 (AMD vs NVIDIA) 는 단순 GPU 가격을 넘어, 성능과 운영 비용을 종합적으로 고려한 실질적인 경제성 분석 지표입니다.
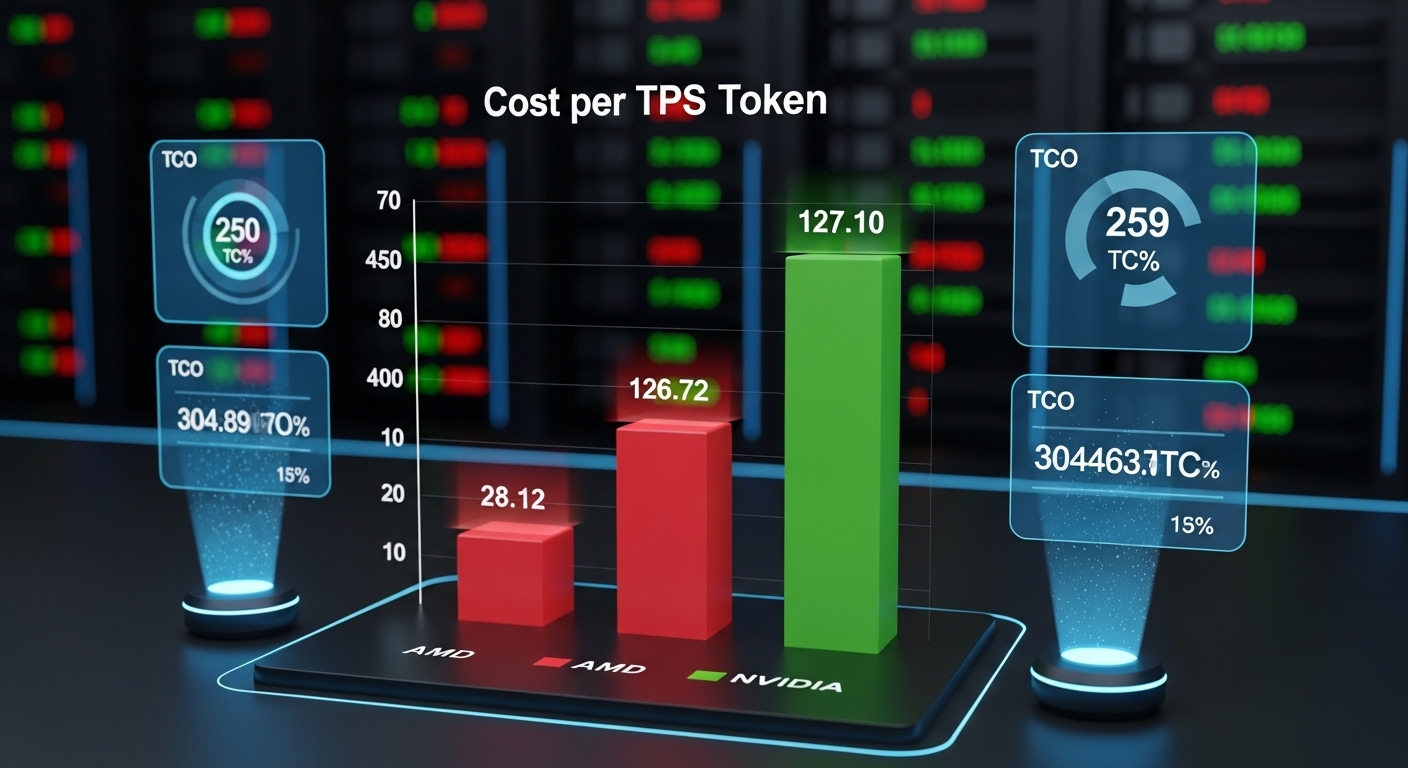
초당 토큰 처리량(TPS) 기반 비용 효율성
GPU의 시장 가격을 가정하고(예: MI300X 약 $15,000, H100 약 $30,000), 이전 섹션에서 확인한 TPS 데이터를 결합하면 '1달러당 얻을 수 있는 TPS'를 계산할 수 있습니다. 예를 들어, MI300X가 H100보다 30% 더 높은 TPS를 제공하면서 가격은 50% 저렴하다면, 달러당 TPS 효율성은 2.6배 더 높다는 계산이 나옵니다. 이는 대규모 추론 인프라를 구축할 때 초기 투자 비용을 획기적으로 줄일 수 있음을 의미합니다.
8-GPU 서버 구성 및 총소유비용(TCO) 비교
단일 GPU가 아닌 8-GPU 서버 전체를 기준으로 TCO를 비교하면 비용 효율성 차이는 더욱 명확해집니다. MI300X 기반 서버는 H100 기반 서버에 비해 초기 구매 비용이 낮을 뿐만 아니라, 3년 운영을 기준으로 전력 소비량, 데이터센터 상면 비용 등을 종합적으로 고려했을 때 총소유비용을 크게 절감할 수 있는 잠재력을 가집니다. 특히 더 적은 수의 서버로 동일한 트래픽을 처리할 수 있다면, 이는 관리 및 유지보수 비용 절감으로도 이어집니다.
클라우드 인스턴스 비용 비교
클라우드 환경에서도 비슷한 경향이 나타납니다. Azure의 MI300X 기반 인스턴스와 H100 기반 인스턴스의 시간당 비용을 비교했을 때, MI300X 인스턴스는 종종 더 낮은 비용으로 더 많은 토큰을 처리할 수 있는 옵션을 제공합니다. 이는 LLM 추론 성능 MI300 vs H100 경쟁이 클라우드 서비스 가격에도 직접적인 영향을 미치며, 사용자에게 더 많은 선택권을 제공하는 긍정적인 효과를 낳고 있습니다.
5. 보이지 않는 힘: 소프트웨어 생태계 (CUDA vs. ROCm)
하드웨어 스펙이 아무리 뛰어나도 이를 뒷받침하는 소프트웨어 생태계가 없다면 무용지물입니다. NVIDIA의 CUDA와 AMD의 ROCm은 수년간의 격차를 보였지만, 최근 그 차이가 빠르게 좁혀지고 있습니다.

- NVIDIA CUDA의 아성: 15년 이상 축적된 CUDA는 AI 개발의 표준과도 같습니다. 압도적인 안정성, 방대한 라이브러리, 풍부한 개발자 커뮤니티, 그리고 TensorRT-LLM과 같은 고도로 최적화된 도구들은 "그냥 작동한다(It just works)"는 강력한 신뢰를 줍니다.
- AMD ROCm의 추격: ROCm은 과거 호환성 문제로 많은 비판을 받았지만, ROCm 6.0 이후 PyTorch, TensorFlow 등 주요 프레임워크를 공식 지원하고 vLLM, Hugging Face와의 통합이 크게 개선되면서 놀라운 발전을 이루었습니다. AMD는 오픈소스 커뮤니티와의 적극적인 협력을 통해 생태계를 빠르게 확장하며 CUDA의 대안으로 자리매김하고 있습니다.
이제 의사결정자는 두 생태계의 장단점을 명확히 이해해야 합니다. 최고의 안정성과 폭넓은 지원이 필요하다면 CUDA가 여전히 매력적인 선택지입니다. 하지만 PyTorch와 vLLM 같은 특정 오픈소스 스택을 중심으로 인프라를 운영한다면, ROCm 역시 충분히 경쟁력 있는 대안이 되었습니다.
6. 미래의 지형도: 차세대 GPU 전쟁 (B200 vs. MI325X)
현재의 선택을 넘어, 가까운 미래의 기술 로드맵을 살펴보는 것은 장기적인 투자 관점에서 매우 중요합니다. NVIDIA와 AMD 모두 차세대 GPU 출시를 예고하며 치열한 경쟁을 준비하고 있습니다.
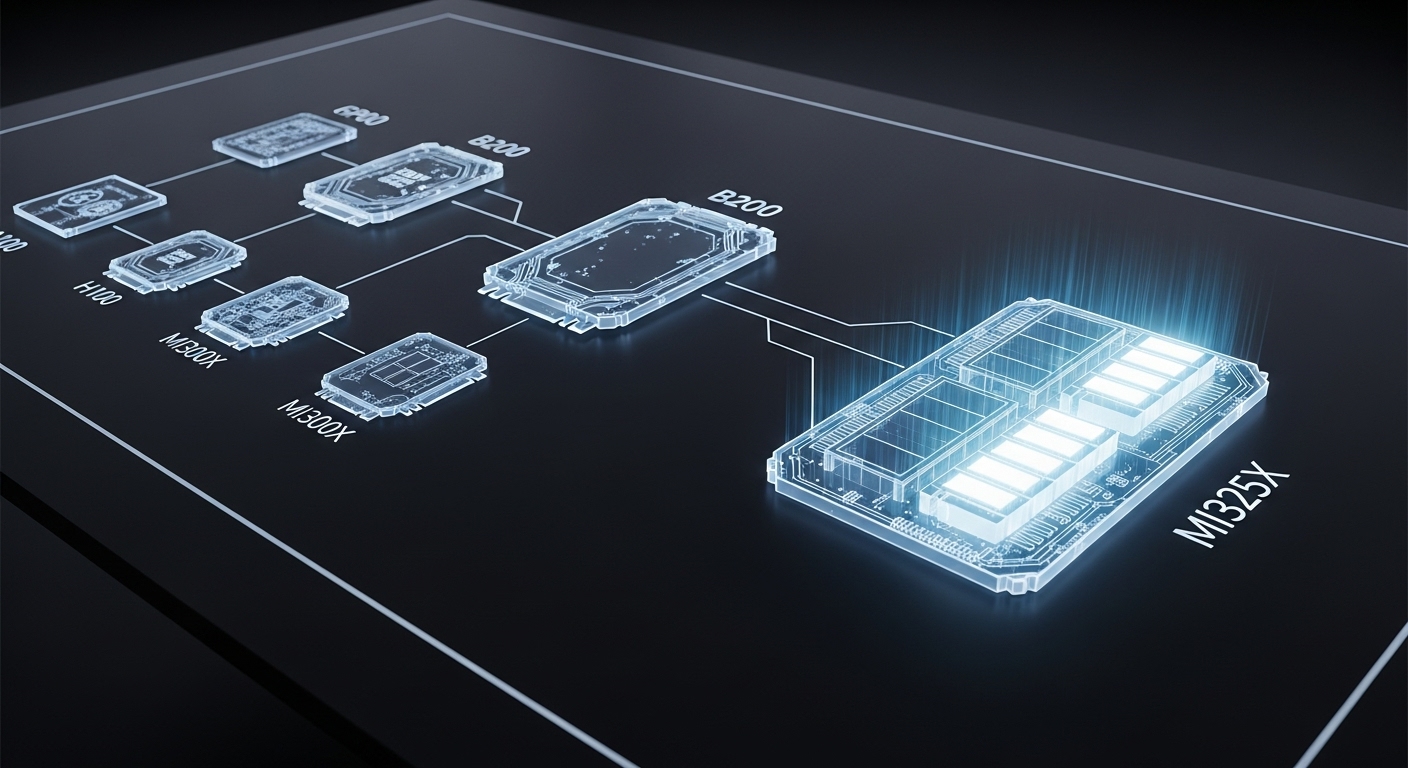
- NVIDIA Blackwell (B200): H100의 후속작인 B200은 더 향상된 FP4/FP6 연산 능력과 2세대 Transformer Engine을 탑재하여 추론 성능을 한 단계 더 끌어올릴 전망입니다. 특히 192GB의 HBM3e 메모리를 탑재하여 MI300X가 가졌던 메모리 용량의 이점을 상쇄할 것으로 보입니다.
- AMD의 대응 (MI325X): MI300X의 후속 모델인 MI325X는 288GB의 HBM3e 메모리를 탑재하여 메모리 용량 우위를 더욱 공고히 할 계획입니다. 차세대 CDNA 아키텍처를 통해 와트당 성능을 개선하는 데 초점을 맞춰, TCO 효율성을 극대화하는 전략을 이어갈 것입니다.
2025년에는 두 회사 모두 메모리와 컴퓨팅 성능을 대폭 향상시킨 신제품을 출시하며 LLM 추론 시장의 경쟁은 더욱 뜨거워질 것입니다. 기업들은 대규모 배치 처리, 저지연성 등 자사의 핵심 워크로드 요구사항을 더욱 명확히 정의하고, 이에 맞는 GPU를 선택해야 할 필요성이 커지고 있습니다.
결론: 당신의 LLM 워크로드를 위한 최적의 선택은?
2024년 현재, LLM 추론 성능 MI300 vs H100 경쟁은 더 이상 NVIDIA의 일방적인 우위가 아님을 명확히 보여줍니다. AMD는 특정 워크로드, 특히 비용 효율성과 대규모 동시성 처리 능력에서 NVIDIA를 위협할 수 있는 수준에 도달했습니다.
그렇다면 당신의 비즈니스를 위한 최적의 선택은 무엇일까요?
MI300X가 유리한 경우:
- 대규모 배치 처리: 수많은 사용자의 요청을 동시에 처리해야 하는 상용 LLM 서비스에 가장 적합합니다.
- 초거대 모델 운영: 단일 GPU에서 70B 파라미터 이상의 거대 모델을 효율적으로 호스팅해야 할 때 강력한 성능을 발휘합니다.
- 비용 효율성 (TCO): 초기 투자 비용과 장기적인 운영 비용을 최소화하는 것이 최우선 과제일 때 최고의 선택입니다.
H100이 유리한 경우:
- 소프트웨어 성숙도와 안정성: 가장 안정적이고 검증된 CUDA 생태계와 개발 도구가 필요할 때 여전히 최고의 선택지입니다.
- 최고의 단일 작업 성능: 고도로 최적화된 환경에서 지연 시간을 최소화하고 가능한 최고의 성능을 끌어내야 할 때 유리합니다.
- 다양한 AI 워크로드: LLM 추론뿐만 아니라, 다양한 AI 모델 학습과 연구를 병행해야 하는 복합적인 환경에 더 적합합니다.
최종적으로, MI300 MLPerf 결과 분석과 추론 TPS 토큰당 비용 비교 (AMD vs NVIDIA) 데이터는 AMD가 AI 추론 시장의 판도를 바꿀 중요한 플레이어로 부상했음을 증명합니다. 이제 기업들은 특정 벤더에 의존하기보다, 자사의 구체적인 워크로드 특성, 예산, 그리고 소프트웨어 운영 전략을 종합적으로 고려하여 가장 현명한 결정을 내려야 할 때입니다.
자주 묻는 질문 (FAQ)
Q: LLM 추론에 MI300X가 H100보다 항상 더 나은가요?
A: 아닙니다. 대규모 배치 처리와 비용 효율성에서는 MI300X가 유리하지만, 낮은 지연 시간이 중요하거나 성숙한 CUDA 생태계가 필요한 특정 작업에서는 H100이 더 나은 선택일 수 있습니다. 워크로드에 따라 최적의 GPU가 다릅니다.
Q: AMD의 ROCm은 CUDA를 대체할 수 있을 만큼 성숙했나요?
A: ROCm은 PyTorch, vLLM 등 주요 오픈소스 프레임워크와의 호환성을 크게 개선하여 많은 LLM 추론 환경에서 충분히 경쟁력 있는 대안이 되었습니다. 하지만 CUDA가 가진 15년 이상의 안정성, 방대한 라이브러리, 폭넓은 커뮤니티 지원 측면에서는 여전히 격차가 존재합니다.
Q: MI300X를 사용하면 TCO(총소유비용)를 얼마나 절감할 수 있나요?
A: MI300X는 H100 대비 낮은 초기 구매 비용과 높은 달러당 TPS(초당 토큰 처리량) 효율성을 제공합니다. 이를 통해 더 적은 수의 서버로 동일한 성능을 달성할 수 있어, 장기적으로 전력 소비, 데이터센터 상면 비용, 관리 비용을 포함한 총소유비용(TCO)을 크게 절감할 수 있습니다.

GPU vs CPU | 당신의 PC, AI 성능을 좌우하는 핵심칩, 무엇이 다를까?
GPU와 CPU의 병렬처리 vs 순차처리 차이를 비교하고, 게임·AI·그래픽 작업에 최적화된 칩 선택 가이드를 제공합니다. 2025년 최신 벤치마크 포함.

AMD 완전 분석 | CPU부터 AI 가속기까지 반도체 혁신 리더의 모든 것
AMD의 Zen 5 CPU, RDNA 4 GPU, Instinct AI 가속기를 완벽 분석. 2025년 최신 기술과 Intel 경쟁 현황, 개발자를 위한 실전 가이드까지 모든 정보를 담았습니다.

DDR4 16GB 성능, 충분한가 | 게이밍, 개발용 메모리 선택 팁
DDR4 16GB 메모리 성능 완벽 분석. 게이밍과 개발 작업에 충분한지, 듀얼채널 구성 방법, 클럭 속도와 CAS 레이턴시 선택 기준까지 2025년 최신 정보로 안내합니다.

클라우드, AI 시대의 사이버보안 전략 | 기업이 놓치면 안 될 2025 핵심 대응 가이드
2025년 클라우드 사이버보안 전략부터 AI 위협 대비, 제로트러스트 구축, 랜섬웨어 대응까지. 중소기업과 대기업이 반드시 알아야 할 실전 보안 체크리스트와 원격근무 보안 방안 완벽 가이드

XSS공격 완전정복 | 취약점부터 대응 전략까지 웹 보안의 핵심 가이드
XSS 공격의 모든 것을 다룬 완벽 가이드. Stored, Reflected, DOM-Based XSS 유형별 방어 전략과 CSP, SameSite 쿠키 설정법을 실전 예제와 함께 제공합니다
LLM 추론 성능 MI300 vs H100 FAQ
LLM 추론 성능 MI300 vs H100는 어떤 상황에서 먼저 확인하면 좋나요?
LLM 추론 성능 MI300 vs H100 | 비용과 성능 완벽 비교는 개념만 훑기보다 실제 업무나 프로젝트에 적용할 수 있는 기준을 잡고 싶을 때 먼저 확인하면 좋습니다. 특히 메모리 용량 및 대역폭: MI300X의 명확한 우위와 관련된 선택 기준을 정리할 때 도움이 됩니다.
LLM 추론 성능 MI300 vs H100를 실무에 적용할 때 가장 중요한 기준은 무엇인가요?
가장 중요한 기준은 목적, 비용, 보안, 운영 난이도입니다. 도구나 기술 자체가 좋아 보여도 하드웨어 스펙 비교표에 맞는 사용 흐름과 관리 책임을 함께 검토해야 실제 성과로 이어집니다.
초보자가 이 글을 읽을 때 어디부터 보면 좋나요?
먼저 상단 요약과 주요 목차를 보고 전체 흐름을 잡은 뒤, 가격·설정·비교·주의사항처럼 당장 필요한 부분부터 읽는 방식이 효율적입니다. 이후 실제 적용 전에는 공식 문서나 최신 정책을 다시 확인하는 것이 안전합니다.
함께 보면 좋은 관련 글은 무엇인가요?
이 주제는 단독으로 보기보다 연관된 기술·도구·업무 자동화 글과 함께 보면 이해가 빠릅니다. 특히 GPU vs CPU | 당신의 PC, AI 성능을 좌우하는 핵심칩, 무엇이 다를까?, 2025년 클라우드 기반 빅데이터 솔루션 운영 최적화 가이드 같은 글을 함께 보면 배경지식과 실무 적용 방향을 넓힐 수 있습니다.


댓글
댓글 쓰기